
In modern biomedical publishing, the tension between statistical significance vs clinical relevance is not theoretical — it shapes what gets funded, what gets published, and ultimately, what influences patient care.
A p-value below 0.05 can secure acceptance in a high-impact journal.
But a statistically significant result does not automatically translate into meaningful clinical change.
That distinction matters — ethically, academically, and systemically.
What Statistical Significance Actually Measures
Statistical significance answers one narrow question:
Is this observed difference likely due to chance?
If the probability of observing the data under the null hypothesis is less than 5%, researchers typically label it “significant.”
According to the National Institutes of Health (NIH), p-values do not measure the size or importance of an effect — only the strength of evidence against the null hypothesis.
A trivial improvement can be statistically significant in a large dataset.
A clinically transformative result can fail significance in a small study.
That is not a flaw in statistics — it’s a misunderstanding of interpretation.
What Clinical Relevance Demands
Clinical relevance asks a harder question:
Does this outcome meaningfully change patient care?
It focuses on:
- Effect size
- Absolute risk reduction
- Number needed to treat (NNT)
- Patient-reported outcomes
- Cost-effectiveness
Regulatory frameworks emphasize clinically meaningful endpoints in drug approval decisions — not just statistical thresholds.
Clinical relevance is about impact.
Statistical significance is about probability.
They are related — but not equivalent.
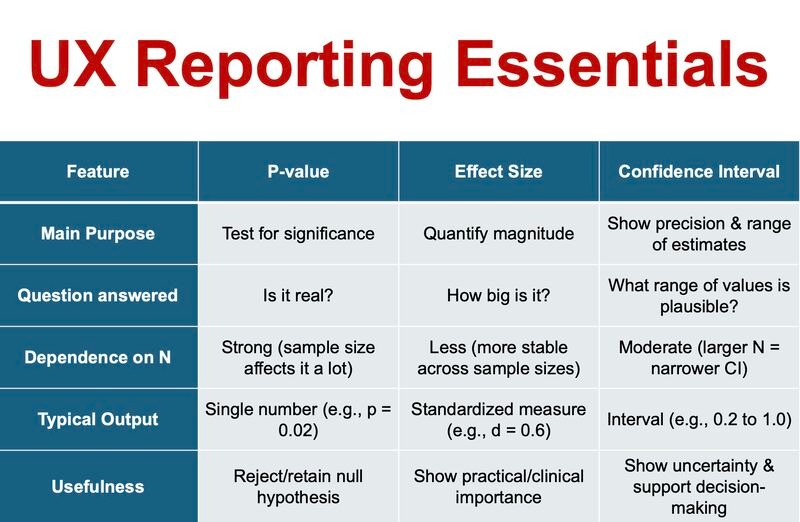
Core Differences at a Glance
Here is a direct comparison:
| Dimension | Statistical Significance | Clinical Relevance |
| Central Question | Is the result likely due to chance? | Does the result meaningfully affect patients? |
| Main Metrics | p-value, confidence interval | Effect size, NNT, absolute risk |
| Sample Size Influence | Highly sensitive | Less distorted by large samples |
| Journal Appeal | High — clear threshold | Variable — requires interpretation |
| Patient Impact | Indirect | Direct |
This table exposes the tension that drives editorial decisions.
Why Journals Gravitate Toward Statistical Significance
Editorial workflows demand efficiency.
A statistically significant result provides:
- Clear acceptance criteria
- Easy comparison across studies
- Reproducible decision rules
In competitive publishing environments, clean statistical outcomes are attractive. Publication bias toward “positive” findings is well documented, including analyses summarized on Wikipedia’s publication bias overview.
This creates a structural preference for statistically significant results — even when the clinical effect is modest.
High-impact journals are beginning to correct this, but the legacy culture remains strong.
The Sample Size Illusion
Large datasets amplify detectability.
With advanced clinical research management software and integrated clinical research management systems, modern trials enroll thousands of participants across multiple sites.
In such settings:
- A 1% difference can achieve p < 0.001
- A tiny change becomes statistically undeniable
But detectability is not importance.
TheAmerican Statistical Association has repeatedly emphasized that p-values should never be interpreted as measures of practical significance.
Large numbers magnify mathematical certainty — not clinical transformation.
Education and the “P-Value Culture”
In many academic programs, including structured environments within a clinical education centre, trainees are conditioned to pursue significance as a marker of success.
Manuscripts are framed around p-values.
Abstracts highlight thresholds.
Peer reviewers scan for statistical confirmation.
Few early-career researchers are equally trained to interrogate effect magnitude, patient-centered outcomes, or implementation feasibility.
Structured reflection through tools like a reading journal or critical appraisal exercises embedded in learning journals can strengthen interpretative maturity.
Critical reading is a skill — not a default.
And journals often mirror the training culture of their contributors.
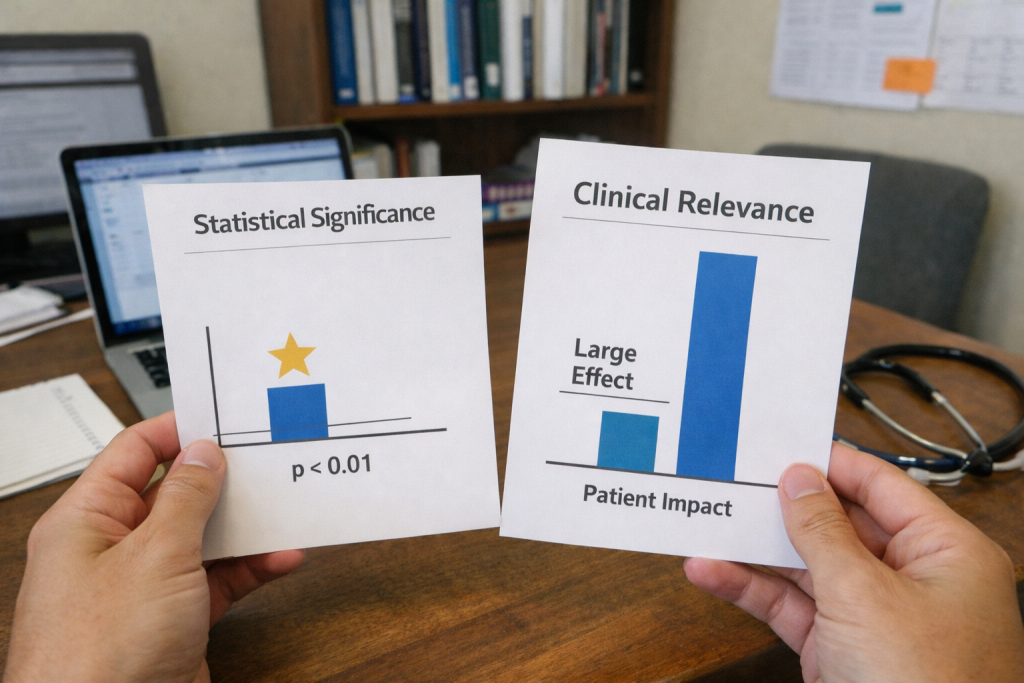
Visualizing the Difference
Below is a simplified conceptual visualization of how the two concepts diverge:
In many cases:
- The blue bar (effect size) is modest
- The statistical marker indicates strong significance
The visual disconnect illustrates why statistical validation does not guarantee meaningful patient benefit.
Interpretation requires context.
A Real-World Hypothetical
Consider two hypertension trials.
Trial A
- 15,000 participants
- Mean reduction: 2 mmHg
- p = 0.001
Trial B
- 120 participants
- Mean reduction: 10 mmHg
- p = 0.07
The Trial A is statistically significant.
Trial B suggests stronger potential impact but lacks power.
Which deserves publication priority?
Journals often choose Trial A because it meets conventional thresholds. Yet from a clinical perspective, Trial B may justify further investigation.
Balancing statistical rigor with clinical foresight is the real editorial challenge.
Want to know what is p-value? Explore in our blog on P-Values Without Context.
The Role of Digital Research Infrastructure
Modern clinical research management software enhances compliance, monitoring, and data integrity.
A robust clinical research management system ensures:
- Protocol adherence
- Transparent reporting
- Audit readiness
- Reproducibility
However, no software can determine whether a statistically significant outcome is clinically meaningful.
That judgment remains a human responsibility.
At ClinicaPress, previous discussions on methodological transparency have highlighted how digital efficiency does not eliminate interpretive bias.
Technology strengthens research operations.
It does not define value.
Why This Debate Matters for Academic Integrity
Overemphasis on statistical significance can encourage:
- P-hacking
- Selective outcome reporting
- Underpowered but sensational framing
- Overstated conclusions
The World Health Organization (WHO) emphasizes outcomes that improve health systems — not just statistical benchmarks.
If journals prioritize significance alone, the incentive structure shifts toward achieving thresholds rather than advancing care.
That erodes trust.
Clinical science must serve patients, not probability cutoffs.
What Journals Should Prioritize Going Forward
A forward-thinking editorial approach should:
- Require reporting of absolute risk reductions
- Mandate transparent effect size discussion
- Encourage publication of robust null findings
- De-emphasize arbitrary p-value cutoffs
- Promote patient-centered endpoints
Statistical significance is a tool.
Clinical relevance is the objective.
The future of high-integrity medical publishing depends on remembering that difference.
Final Perspective
The debate over statistical significance vs clinical relevance is not about discarding statistics.
It is about contextualizing them.
Statistical significance tells us whether an effect is likely real.
Clinical relevance tells us whether it is worth acting on.
Journals have historically leaned toward the former because it is easier to quantify.
But ethical, patient-centered science requires that we prioritize meaningful impact over mathematical neatness.
Evidence should change practice only when it changes outcomes.
Anything else is precision without purpose.
Now try implementing your knowledge statistical significance vs clinical relevance.



